Persistent storage patterns for Docker in production
July 19, 2016 - by Casey Bisson
The conventional wisdom is that containers are great for stateless applications, but inappropriate for stateful apps with persistent data. If this is true, it's not because the technology isn't up to it, it's because the patterns for managing persistent data and stateful applications are not commonly understood. The challenge isn't so much about how to persist state, but how to do so without compromising the agility and automation that we love about containerization in the first place.
I have seen this future where applications of all types can be easily and automatically deployed, where scaling -- even for clustered systems with persistent state -- can be done with a button press, and even backups and recovery are automatic. Let me show you how....
"State..." you keep using that word...
Most applications, even those we call "stateless," keep some sort of state. That state can be as simple as where the application is in the execution flow, or as important as my Pokemons' CP (or my bank account). "Stateless" and "stateful" don't so much describe the application as the value of the data that makes up its state and the cost of recovering it.
A random number generator is stateless because we expect a different value from it every time we run it. We could easily Dockerize it, and if the instance fails, we can re-provision it elsewhere without worrying about it changing its behavior because it's now running on a new host.
My bank account, however, is not stateless. If the bank account app has to be re-provisioned on a new server, it better have all the same data as it had on the first server, or else a number of people are going to be angry. We can all hope for a bank error in our favor, but even then somebody's angry.
Yet statefulness is not strictly dependent on the type of data represented by the application. Consider an in-memory cache like memcached. Memcached is often used to hold very valuable data, including banking data, but we don't consider it stateful because we've constructed our applications in such a way that we can recover memcached's state. There's a performance cost when doing so, but no unique data is lost.
State and the statefullness of an app is truly about the cost of recovery of that state, and that cost can depend on the nature of the data that represents the state and the architecture of the application.
"Persistent..." you keep using that word...

This starts out easy. On our laptops, data in RAM is not persistent, but data on the hard drive (or SSD, praise SSDs) is persistent until we delete it (or the device fails). But in the cloud, and any time we're building resilient applications, this simple notion of persistence gets more complex.
Increasingly, we want servers to be disposable. Sometimes we call this immutable infrastructure, but the goal is that we can go to any server anywhere and run our app. And, if that server fails, we can throw it away -- dispose of it -- and go to another. This is necessary in public clouds because we're just renting the server, or a portion of it, and it's necessary for resilient applications because we have to build them in a way that can survive the failure of the hosting infrastructure.
But, the disposability of the servers is incompatible with our understanding of persistence of data that we learned from our laptops. How can we build stateful applications with persistent data if we don't have any claim to the hard drives or SSDs on which we're persisting our data?
Some clouds and a handful of vendors introduced an expensive twist on persistent data: move the data to a different set of servers and connect it back to the application servers over a network of some sort. That network could be fiber channel or TCP/IP, but it's a network, and it increases the distance between the data and the applications that need it. As distance increases, so do error rates and latency, while throughput and maximum performance decline. ...And those increased error rates include network partitions that separate the applications from their data.
Putting data in a different set of servers and connecting it over the network doesn't make the data any more persistent, but it does make it more portable. Unfortunately, the systems that most need persistent data are often those that suffer the most by the poor and unreliable performance of remote storage. Most database vendors, for example, caution users of poor performance when using remote storage, and that's when it's working well. The failure modes of remote storage are rather spectacular (example 1, and 2, and a cautionary tale), raising both the costs and stakes of solutions that attempt to make persistent data portable at the infrastructure level.
Finally, of course, this doesn't actually solve the problem and eliminate pets, it just moves the pets to a different set of servers, and we pay a very high price in terms of performance, reliability, and real dollars for it.
Where is all this going?
Let's agree that persistence is separate from portability, and the statefulness of an application (and the disposability of its servers) is about the cost of reconstructing that state.
Consider: persisting data on a server can turn it into a pet...

...while infrastructure solutions to making persistent data portable are a Venn diagram that never quite comes together in the middle, forcing us to choose two out of three: speed, reliability, portability.
But, some applications handle state and persistence better than others. Consider databases that have self-clustering features, like Couchbase. Couchbase manages data portability at the application level.
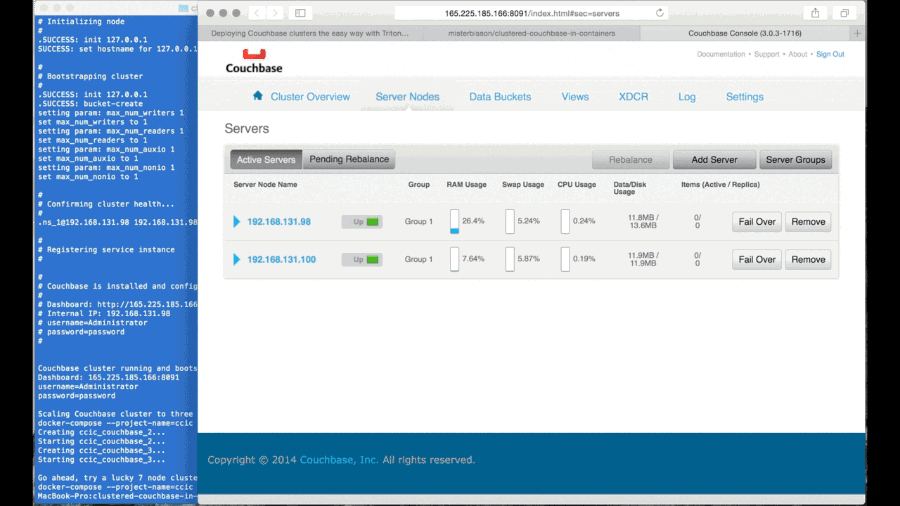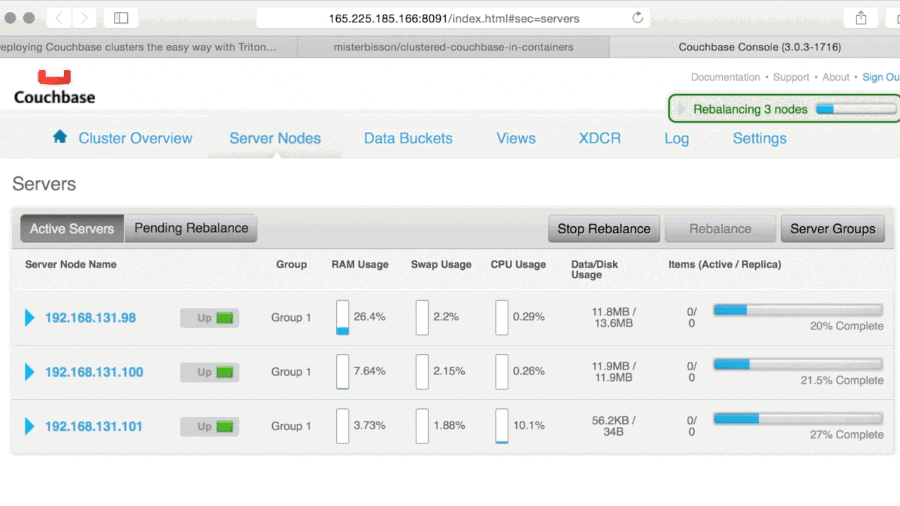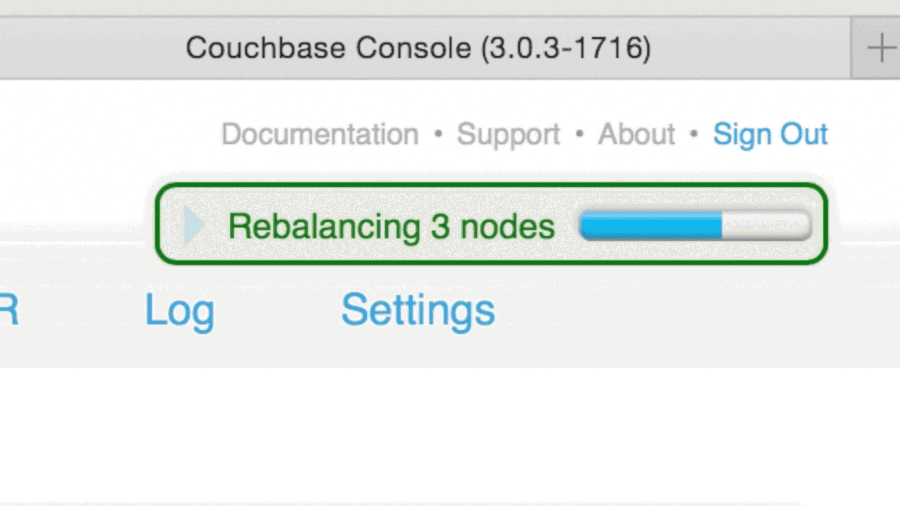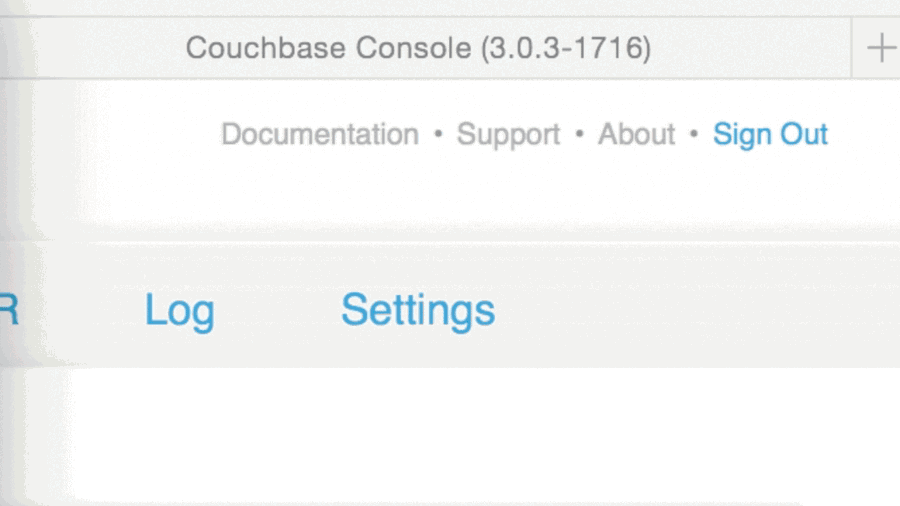
When I join a new Couchbase instance to a cluster, it automatically replicates and re-shards the data to that new instance. In fact, many of the operational tasks that are necessary for the previous generation of databases are completely automated. This is also true for failures: as long as we don't lose too many Couchbase instances too fast, the data and state will be reliably persisted by the remaining instances in the cluster. Couchbase even supports cross-data center replication at the application level. Combined, this entirely eliminates any need for remote storage at the infrastructure level.
As a practical matter, Couchbase in containers is actually stateless as far as the infrastructure and scheduler are concerned. As long as the scheduler and supervisor1 keep enough instances running, Couchbase's automated re-sharding and replication features will take care of the rest.
Patterns we can use
Different applications offer different levels of automated operations, and not every application is built to automatically manage all the various data that represent its state. What can we do, short of abandoning or rewriting those apps?

The first question is what kind of stateful data are we talking about?
Some of the most common state data is configuration related. That configuration, including keys and other secrets, is often written to disk in various files. This data is (or should be) easy to recover when provisioning instances, since we can't provision and scale automatically if we can't configure the instances automatically.
User-generated content presents other challenges. This can be text, video, my Pokemons' CP, or bank transactions. Each type of data deserves consideration separately.
Configuration
Often times, the most dynamic configuration details are those that connect service X to service Y. Connecting my app to its database is one example. That process is called discovery, but most applications/services simply treat it as configuration along with other configuration details. In order for an app to be scalable and resilient, it's necessary to update this configuration while its is running. That is, as we add or remove instances of a service, we've got to be able to update all the other services that connect to it. Example: if my database is under load and I need to add a few more instances to improve performance, all the things that need to connect to it need to know about the new instances. Otherwise, the new instances will sit idle and do nothing to improve application performance. We have to go through the same process if an instance of the database ever fails: if we can't update the database's clients, we'll get a lot of failed requests.
The good news is that this kind of dynamic configuration is easy, and we have a tutorial on how to do it.
Other configuration details can include performance tuning parameters and other details, and there's healthy debate about whether or not those details belong in the application repo (so they can be versioned and tracked) or in dynamic storage so they can be changed without re-building and re-deploying the application. A compromise solution can be automatic replication of repo contents to the configuration store using a tool like git2consul. Exactly how to handle this other configuration data depends on the specific application, but generally:
- Keep configuration data, and maybe templates too, in Hashicorp’s Consul, or another strongly consistent distributed key/value store
- Gather configuration details at runtime
- If the application expects them to exist on disk, use in-instance storage
Secrets
To our apps, secrets generally just configuration details, but to us they're more sensitive. Hashicorp's Vault is a general purpose solution for securely storing secrets, but CI/CD solutions often also include secret management features (Shippable is one).
- Keep secrets in Vault, or another secure secret management service
- Gather secrets at runtime
- If the application expects them to exist on disk, use in-instance storage
Databases
Databases are often the canonical example of stateful applications that are difficult to Dockerize. Unfortunately, there's also a lot of bad advice and hokum about how to do so.
Dockerizing a database is pretty much the same problem as implementing a database in the cloud, and that's pretty much the same problem as building out a resilient database implementation: automation. The problem with automating many database operations is the importance of objects on the filesystem. Automating replication of MySQL and PostgreSQL, for example, requires automatically copying the contents of the filesystem to the new instance. Postgres and MySQL have documentation explaining how to do it, but they don't ship with tools that get the job done in a consistent and reliable way (or at all). Newer databases often automate some of these operational tasks, as in the Couchbase example above.
Nonetheless, this automation can be implemented and Autopilot Pattern MySQL demonstrates how. What that implementation adds to typical MySQL is lifecycle awareness. As database operators, we know there are things we have to do when we start a new database instance: are we joining an existing database cluster or starting one new? If joining an existing cluster, we need to bootstrap the replica. That start of the database lifecycle is now automated using the Autopilot Pattern, as are backups throughout the database's lifecycle. The implementation also (optionally) automates the election of a new primary after a configurable timeout if the existing primary fails (ending its lifecycle).
The data/state is persisted at multiple levels:
- The replication process duplicates state across multiple database instances; any surviving instance and be used to bootstrap a new instance
- The state of the primary instance is periodically backed up to an object store; this assures some level of data survivability, even if the entire running cluster is lost
The result is that this MySQL implementation is now stateless, and the scheduler does not need to do any orchestration of the data and we have no need for unreliable or slow remote storage. Those details are specific to the MySQL implementation, but generally:
- Use in-instance storage
- Distribute data among multiple instances
- Upgrade the database by adding new replicas/peers and removing old replicas/peers (promote replicas to primary as needed)
- Back up using DB-specific solutions
Shared data
Shared data presents a special case for applications that are inching closer to the legacy category. That said, some of those applications will probably be with us for a long time. One very common example is WordPress, the almost ubiquitous blog software. WordPress uses MySQL to store its text content and much of its configuration, but user uploaded images and other blobs are stored on the filesystem.
There are WordPress plugins to use object storage, but it's not the default, and there are quite a number of plugins that are incompatible with that approach. So, in order to scale WordPress to multiple instances without incompatibilities, we'll need a shared filesystem across. Without that shared filesystem, each instance would have an independent (inconsistent/partitioned) portion of the user uploaded files.
Our Autopilot Pattern implementation of WordPress uses NFS as the shared filesystem for just that reason, but generally:
- Use Manta Objects, or other object storage if you can
- Use a shared filesystem (NFS) as a last resort
Things to avoid
Keen readers might be wondering why I haven't suggested solutions like mapping volumes in from the Docker host or using Docker volume drivers. In short, I'd suggest avoiding those, especially anything that simply moves the persistence problem from the container to the underlying host. That might make it possible to ignore the challenges of data and state management in the container, but it doesn't solve the problem for our applications. We'll still need to find a way to manage the data, and doing it outside the container means we're doing it without the benefit of all the tooling and state awareness that exists in the container. Worse, it turns those container hosts into pets and can constrain our applications to specific hosts. Working around that problem outside the container requires much more complex, application-specific orchestration in the scheduler and a larger infrastructure management team and SREs to make it work. On top of that, separating developers from the operational details of their apps is the leading cause of "works on my machine" (see Sci-Fi DevOps for more).
The problems with remote storage are discussed above, and that applies to remote storage accessed via Docker volume drivers as well. Most of the problems of remote storage also apply to distributed storage, with the added challenge of (in-)consistency, partitions, stale reads, lost writes, an irreconcilable changes. The promise of distributed storage is the performance of local storage with the convenience of shared filesystems, but it's a particularly thorny problem and all the solutions so far have demonstrated ugly failure modes that raise serious questions about their reliability and consistency.
Again, the needs of your application will vary, but it's generally best to avoid:
- Mapping
-vvolumes from the host --volumes-from- Most Docker volume drivers
- Distributed filesystems
Every application can be stateless
Any application that assumes a filesystem can be made stateless by automatically backing up the filesystem contents while the container is running and restoring the filesystem when the application is started. The MySQL example above does just that, though it uses application-level replication as the primary mechanism to distribute state among a number of instances for performance and survivability.
We can use the same approach for applications that don't feel like databases. Imagine running Gerrit Code Review in a container: by backing up the filesystem to an object store (or queueing a backup) any time a hook is fired, we can get a reliable copy of the application's state (the Postgres DB should be backed up and replicated separately). If we then design our container to restore the contents of that backup at start time, we can make the application highly durable and resilient without needing any infrastructure support.
And, by triggering backups based on application activity, we can be sure we're backing up the filesystem when there are meaningful changes, and not more or less frequently.
What we've done is make Gerrit stateless to the scheduler. This doesn't mean Gerrit won't ever have downtime, but we've made it easy to replace Gerrit or simply move it to a new server when we need to with minimal downtime. This is because this hypothetical implementation of Gerrit can automatically recover its state from the backups we've made and pick up right where it left off. We've made it stateless enough that the scheduler doesn't have to do any complex orchestration and without any magic infrastructure. Instead, we've done it with reliable tools and systems that have served our applications for years.
This is separate from making an application share consistent state across multiple instances for scale and availability. Shared state often requires support in the app. For Gerrit specifically, the team has decided not to add clustering/shared state features based on their assumptions about the cost of downtime. Conversely, the MySQL and Couchbase examples above demonstrate how applications can be designed to share state across multiple instances and be operated in a way that is still stateless to the scheduler.
Pick your application, challenge me
Don't think it's possible to make any application stateless? Try me. Email DevOps@joyent.com with your questions. Be sure to include links to repos and documentation with your question so I can see the details. I'll try to answer your questions here on the blog.
-
The scheduler controls when and where containers run, the supervisor ensures those containers continue to run and triggers re-scheduling of any containers that fail. ↩
