 Converged Analytics
Converged Analytics
Simplify Data Analytics and Processing
Why Triton Converged Analytics?
Near-Zero Latency
Compute processing is available on demand, on data at rest in Triton Object Storage. No movement of data over the network for processing is required.
Simple
simple
Elastic
flexible
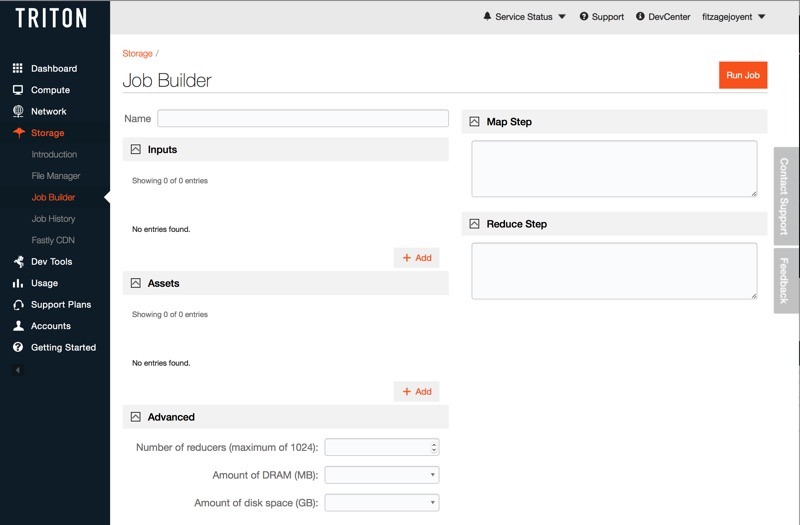
What Capabilities Does Triton Converged Analytics Provide?
Serverless Compute
Leverage pre-provisioned containers to run analytics jobs directly on data in Triton Object Storage. No need to deploy servers and software, or to copy data to compute nodes for processing.
No Frameworks, Just Unix
No need to learn MapReduce or ETL frameworks. Analytics jobs support Unix scripts in shell, R, awk, grep, Python, node.js, Perl, Ruby, Java, C/C++, and ffmpeg.
Debug Jobs and Objects
Debug multi-phase maps and reducers. An interactive shell inside an analytics job can run directly on the stored object to inspect it, re-run the job, and save in-flight files.
Multi-Phase MapReduce
Tune MapReduce init, task types, and resource allocations. Run phased reducers with Outputs (maggr, mcat, mpipe, mtee, msplit) feeding cascading reducers – unix pipeline style.
ETL (extract, transform, load)
Execute assets (scripts) in any language to perform image conversion, transcode video, generate databases from access logs, and other format conversions.
What can I do with Triton Converged Analytics?
Data Mining
Using standard tools like NumPy, SciPy and R
MapReduce
MapReduce processing with arbitrary scripts and code without data transfer
Log Analysis
Clickstream analysis, MapReduce on logs
Image Processing
Converting formats, generating thumbnails, resizing
Video Processing
Transcoding, extracting segments, resizing
Text Processing
Text processing including search